Based on the latest data and forecasts from Japan, it would be premature to declare the end of that country’s deflationary period. The Bank of Japan (BOJ) forecasts that consumer prices will continue to fall through the 2004 fiscal year, which ends in March 2005, albeit only at a 0.1% to 0.2% annual pace.
- An explicit CPI target?
- Increasing short-term interest rates
- Reducing commercial bank excess liquidity
- Conclusion
- References
Pacific Basin Notes. This series appears on an occasional basis. It is prepared under the auspices of the Center for Pacific Basin Studies within the FRBSF’s Economic Research Department.
Based on the latest data and forecasts from Japan, it would be premature to declare the end of that country’s deflationary period. The Bank of Japan (BOJ) forecasts that consumer prices will continue to fall through the 2004 fiscal year, which ends in March 2005, albeit only at a 0.1% to 0.2% annual pace. Still, it is clear that the threat of deflation in Japan has been reduced. Most recently, the Bank of Japan has forecast positive inflation of 0.1% for the 2005 fiscal year, which runs from March 2005 through March 2006, although BOJ Governor Fukui was quick to point out that the precise timing of the end of deflation was still unclear.
Part of the credit for reducing the threat of deflation must go to the BOJ, which has been conducting expansionary monetary policy in the form of maintaining short-term interest rates at close to their minimum attainable zero values since 1999. More recently, the BOJ has also been flooding commercial banks with excess liquidity to promote private lending, leaving commercial banks with large stocks of excess reserves, and therefore little risk of a liquidity shortage. Together, these policies are commonly referred to as the BOJ’s “quantitative easing” policy.
As BOJ Governor Fukui (2004a) recently noted, the quantitative easing policy would likely become more stimulative if it were maintained as Japan’s economic recovery solidifies, given that the increased opportunities for profitable investment would normally push interest rates upward in the absence of a response by the central bank. Maintaining a zero interest rate in the face of such upward pressure would therefore require even more aggressively expansionary monetary policy. In the limit, continued stimulus after a recovery has taken hold could cease to be sound countercyclical policy and instead become a source of inflationary pressure.
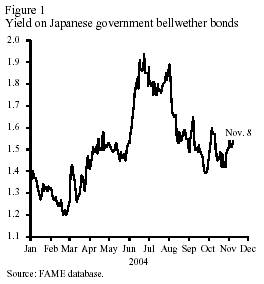 Upward movements in 10-year Japanese government bond yields between February and June this year suggest that the Japanese public expects a move towards positive inflation, or a tightening of Japanese monetary policy, or some combination of the two (Figure 1). Although recent weak news has brought the 10-year yield back down to spring 2004 levels, it is still about 20 to 30 basis points above its 2004 low.
Upward movements in 10-year Japanese government bond yields between February and June this year suggest that the Japanese public expects a move towards positive inflation, or a tightening of Japanese monetary policy, or some combination of the two (Figure 1). Although recent weak news has brought the 10-year yield back down to spring 2004 levels, it is still about 20 to 30 basis points above its 2004 low.
Japan’s impending success in ending deflation therefore raises the question of the best “exit strategy” from the current accommodative monetary policy to one that is consistent with Japan’s incipient economic recovery. Recent speeches by Japanese government officials, as well as releases of the minutes of recent central bank monetary policy meetings, reveal that the BOJ is currently wrestling with this issue. BOJ Governor Fukui (2004b) recently identified two policy actions associated with ending the expansionary policy: First, nominal short-term interest rates will be raised from their current zero levels; second, there will have to be a reduction in the stock of excess reserves currently held by commercial banks in their BOJ current accounts. In this Economic Letter, I discuss the policy issues surrounding the exit from the BOJ’s quantitative easing policy.
Considerations of the appropriate strategy for exiting from the BOJ’s quantitative easing policy raise at least two controversial questions. First, should the BOJ follow an explicit rule concerning exactly when to begin to exit the quantitative easing policy? Second, should such a rule be explicitly communicated to the public?
The BOJ has announced that it will maintain its quantitative easing policy until “…the year-on-year change in the CPI registers zero percent or higher on a sustainable basis” (Fukui 2004a). Governor Fukui noted that this policy rule provided clarity about the BOJ’s decision process for terminating quantitative easing, and therefore served to solidify market participants’ expectations of low Japanese interest rates going forward.
At the same time, this policy rule leaves the central bank with some discretion over the timing, as people may hold different beliefs about the set of conditions that would satisfy evidence that changes in the core CPI were non-negative on a “sustainable” basis. As such, while the BOJ announcement enhances the transparency of its policy, there remains some degree of opacity, both in the communication of the rule to the public and in the rule itself.
It is apparent that the policymakers at the BOJ understand this. The minutes of the June 25 Monetary Policy Committee meeting reveal that the Committee discussed whether the BOJ should present an explicit higher numerical target for the CPI to better stabilize expectations (BOJ 2004). One member advocated the idea, while another agreed that a higher numerical target was “worth considering.” The latter stressed that the intent of such an announcement would be to clarify the BOJ’s commitment to the public concerning the conditions for raising rates, rather than strengthen them. In the end, the Committee decided not to pursue such a strategy. One member argued that setting a higher condition would impair “…the Bank’s flexibility in the conduct of monetary policy.”
The tradeoff between transparency and flexibility in monetary policy has been noted in the economics literature for some time. While explicit policy rules may make monetary policy more transparent, and thereby serve to anchor agents’ expectations, rules that are too rigid may hinder policy flexibility, particularly in the event of unforeseen developments. For example, in arguing against the adoption of an explicit inflation targeting rule for the United States, Governor Kohn (2003) argued that “…the U.S. economy has benefited from the flexibility that the Federal Reserve has derived by eschewing a formal inflation target. By flexibility I mean not frequent changes in long-term objectives but rather the freedom to deviate from long-term price stability, perhaps for a while.”
Increasing short-term interest rates
Another issue concerns the proper pace of raising short-term interest rates from their current zero levels. For example, suppose policymakers knew exactly what long-term interest rate would be consistent with neutral monetary policy. Should policymakers pursue a “gradualist” approach, which moves the interest rate in small steps towards this goal, or a “discrete” approach, which jumps to this higher rate of interest very quickly.
Arguments for gradualism in monetary policy have been made on the basis that such policies serve to anchor agents’ expectations (for example, Woodford 1999). By moving slowly in small steps, advocates claim, the central bank can better convey the future interest rate path to the public. However others, such as Rudebusch (2001) argue that anchoring public expectations requires only that central bankers credibly convey the future interest rate path and, in particular, does not imply any constraint on the form of that path. Indeed, Rudebusch argues that the expectation of a constant interest rate path, which would be the one that would emerge in the absence of gradualist policy, may be the simplest and therefore the easiest interest rate path to convey.
In the case of Japan it appears that the paramount concern would be to maintain expectations of positive inflation going forward, rather than anchoring the level of expected interest rates. By moving toward a neutral stance only slowly, policy would remain accommodative on the way up; and to the extent that it is accommodative, it allows the economy to absorb a negative shock that might otherwise lead to deflation. A gradualist policy, therefore, serves to ensure positive inflation expectations.
Reducing commercial bank excess liquidity
The BOJ has also purchased large amounts of government securities, leaving Japanese commercial banks holding large stocks of excess reserves. Current bank balances lie between 30 and 35 trillion yen, far in excess of the banks’ required reserves, which total about 6 trillion yen. As Fukui noted (2004b), one of the components of the BOJ exit strategy will concern drawing down these excess reserve levels. In order to repurchase these reserves, the BOJ would typically sell securities, such as Japanese government bonds, to the commercial banks. This transaction need not have an impact on the overall Japanese money supply, as the BOJ could offset it by purchasing an equal amount of securities on the open market.
However, the motivation for the excess liquidity policy was the perception that banks with excess liquidity would be willing to maintain a higher ratio of loans to deposits than they might otherwise, because they are less likely to face liquidity problems due to an unforeseen adverse shock. As such, if the excess liquidity policy is having a stimulating effect on bank lending, its removal could have some damping effects.
Nevertheless, the BOJ has made it clear that it does not intend to initiate the end of the quantitative easing policy until the Japanese economy is on a sustainable positive inflation path. Along such a path, the commercial banks would be likely to choose to draw down their excess reserves on their own. As long as there is modest deflation, the returns to banks from holding excess reserves is slightly positive, net of the additional operational costs associated with holding the excess. However, once deflation is ended and interest rates again become non-zero, Japanese banks will face a positive opportunity cost of maintaining excess reserves at the central bank. They can respond to this change in two ways. They can increase their lending activity, which would raise their required reserves, or they could purchase government securities from the central bank. The likely outcome is a mix of these two strategies which would lead to a decline in the stock of excess reserves.
The monetary policy challenges raised by the beginning of the end of the Japanese deflation era are less difficult than those previously faced, but they are challenging nonetheless. Moving from an extremely accommodative monetary policy stance to one that is proper for more conventional circumstances at a time when expectations concerning positive inflation have yet to be firmly established raises the concern that an adverse shock may lead to a reversion back to deflationary expectations.
Because the BOJ is aware of the risks involved, it has taken great efforts to convey to the public a policy rule under which quantitative easing will not be ended until there is evidence that the Japanese economy has safely emerged from deflation. Nevertheless, the approaching end of quantitative easing demonstrates the tension between transparency and flexibility in monetary policy. As discussed above, some have criticized the BOJ’s stated policy, arguing that ambiguities could still arise under the stated rule that could be eliminated through the adoption of a formal policy rule. However, the BOJ has chosen a compromise solution, under which the criteria for moving away from the quantitative easing policy is relatively transparent, but retains some degree of flexibility to allow policymakers to respond to unforeseen circumstances.
Mark M. Spiegel
Vice President, International Research, and
Director, Center for Pacific Basin Studies
[URLs accessed November 2004.]
Bank of Japan. 2004. “Minutes of the Monetary Policy Meeting on June 25, 2004.” http://www.boj.or.jp/en/press/04/press_f.htm
Fukui, Toshihiko. 2004a. “Achieving Sustainable Economic Growth and Overcoming Deflation.” Summary of a speech at the Yomiuri International Economic Society, Tokyo, May 13. Bank of Japan. http://www.boj.or.jp/en/press/04/press_f.htm
Fukui, Toshihiko. 2004b. Untitled. Summary of a speech at a meeting in Osaka on September 2. Bank of Japan. http://www.boj.or.jp/en/press/04/press_f.htm
Kohn, Donald L. 2003. “Remarks.” Delivered at the 28th Annual Policy Conference: Inflation Targeting: Prospects and Problems, Federal Reserve Bank of St. Louis, October 17. http://www.federalreserve.gov/boarddocs/speeches/2003/200310172/default.htm
Rudebusch, Glenn D. 2001. “How Sluggish Is the Fed?” FRBSF Economic Letter 2001-05 (March 2).
Woodford, Michael. 1999. “Optimal Monetary Policy Inertia.” The Manchester School Supplement, pp. 1-35
Opinions expressed in FRBSF Economic Letter do not necessarily reflect the views of the management of the Federal Reserve Bank of San Francisco or of the Board of Governors of the Federal Reserve System. This publication is edited by Anita Todd and Karen Barnes. Permission to reprint portions of articles or whole articles must be obtained in writing. Please send editorial comments and requests for reprint permission to research.library@sf.frb.org