
Behind the Scenes: Building the SF Fed Data Explorer
Erin Crust
December 1, 2022
In September 2022, the Economic Research department launched the SF Fed Data Explorer. This interactive tool allows you to explore and download data for various demographics of people in the U.S. labor market. Erin Crust, a Research Associate from the Economic Research department, shares the story behind the development of the SF Fed Data Explorer.
So many important decisions are informed by data, which means the ability to influence how data is used and talked about is an incredible opportunity for anyone to contribute. This brings more unique perspectives and new ideas to the forefront—making the conversation richer and more productive for everyone.
However, if you don’t have some of the technical skills like coding or statistical analysis, finding the right data and knowing how to use it can feel like a huge obstacle—but it doesn’t have to be.
From personal experience, I know that creating a large-scale application like the SF Fed Data Explorer from scratch can be intimidating, especially for someone who has never attempted anything like it before. I believe the best way to overcome this is to jump right in on a project you care about and learn as you go. I hope that sharing how I approached working on the Data Explorer will make that leap less daunting for others.
Thinking about Design
Personally, I enjoy working with rich data like the Current Population Survey (CPS). The CPS provides microdata from a monthly survey where households can respond about their employment status and other details. Whenever I see interesting or unexpected trends in the data, I love being able to ask questions, make some hypotheses, and then dig back into the data to test out my ideas. In fact, working with the CPS microdata was my first exposure to economic research when I was an undergraduate student. It was an empowering experience for me as a new researcher, but it also taught me that processing the data and assembling your own series requires some technical knowledge.
Because of this, I wanted to replicate that experience of exploration and discovery for others, to make it more accessible to people without a technical background. That’s part of what our team set out to do with the SF Fed Data Explorer.
The overarching design goal was to mimic how researchers engage with the data—how they develop questions, investigate possible answers, and then fine tune their search. With that in mind, we wanted this tool to provide seamless and intuitive access to a wide range of data so people could easily drill down from the larger data set into smaller groups without having to search through a lot of separate data series. Next, we wanted people to be able to easily adjust the data in ways economists commonly do, like adjusting for seasonal changes or inflation, averaging over a number of months, or indexing the data to a base date for ease of comparison.
Finally, it was important to include a collaborative aspect in the design, so people could share their work with others or save a specific chart for future reference. We achieved this by developing chart codes that capture not just the series you are looking at but also any settings you have applied to them.
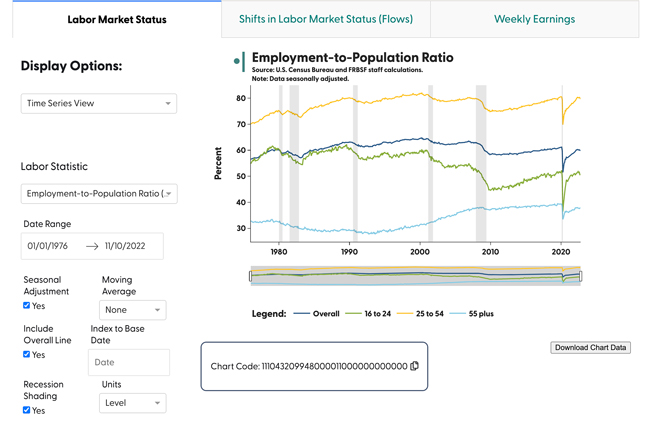
How Does It Work?
To bring our ideas to life, we programmed a combination of preprocessing and dynamic calculations that let the SF Fed Data Explorer quickly display many different possible series.
When new CPS data are released, we calculate seasonally adjusted and non-seasonally adjusted series for all the different statistics and demographic breakdowns. These calculations use very large data sets and take a long time to process, so doing this prep work saves a lot of time for other users. We then compile the data into separate files for each statistic that appears in the Data Explorer. Each row in these larger files includes a flag to indicate the demographic group and whether the data have been seasonally adjusted.
When someone selects a labor statistic, the Data Explorer draws from the specific data associated with that statistic to make the chart.
Some features—like the date range boxes, the seasonal adjustment check box, or the demographic group dropdown menus—tell the charting function what rows to include in the plot from the data set they created earlier. Others—like the moving average dropdown and the feature that lets you index the data to a base date—involve simple transformations of those series without additional information from the larger source data set, so those calculations are done dynamically, as users interact with the dashboard. That way, we can still provide a lot of flexibility in terms of how users might want to display the data without having our preprocessed data files become unmanageable.
Other functions in the app’s code observe when you switch between modes and display options. These functions make sure that users only see the features that are relevant for the mode they are using. For example, when you switch to the “Build Your Own Chart” mode, we built in a function that makes the options for that mode visible and hides the dropdown menu for the “By Demographic Groups” mode. Then, as you make choices for the “Demographic Category” and “Refine” dropdown menus, another function activates to display the next level of demographic options. This helps users understand what options are available to them at any given moment.
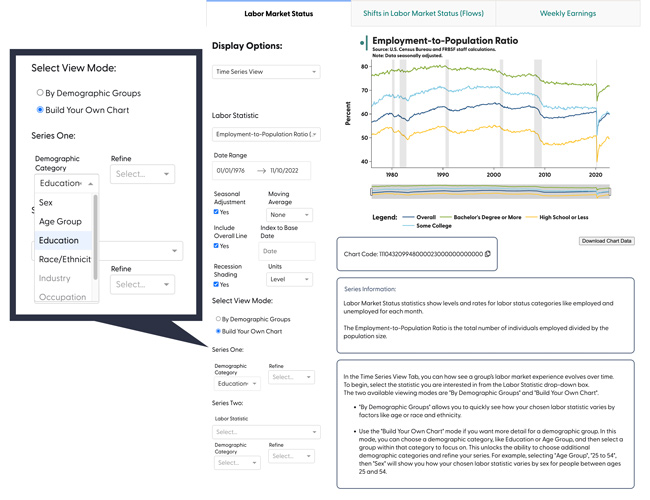
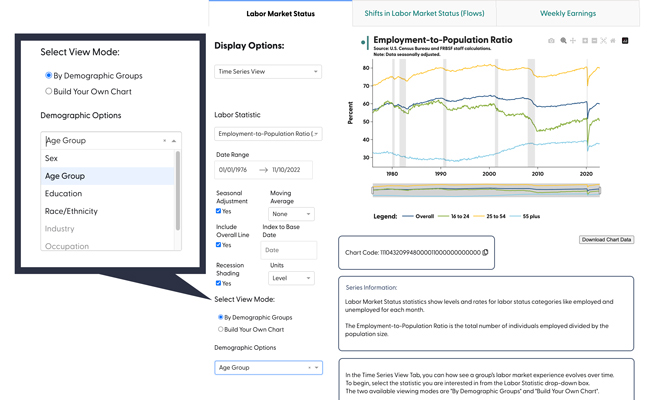
All these features also feed into the function that generates the chart codes. Each digit of the 30-digit chart code encodes some piece of information about the options selected, so the same combination of controls will always produce the same chart code. When you copy this code into the chart code box at the top of the app, a separate function decodes this information and uses it to set the control panel features to produce the correct chart.
About the Process
While I was familiar with the CPS data and could code in Python to process the data, I had never made any kind of program with a user interface before this project. Luckily, there are many amazing online resources for learning more about programming, so I found a tutorial for building dashboards in Python and gave it a try.
Of course, the first version of the Data Explorer was much simpler than the final product. Given that the whole process from beginning to launch took nine months, I realized that this was what made research exciting. Every time our team brainstormed, we thought of new features we wanted to include in the app to make it more helpful and customizable. The research process may not always follow the anticipated trajectory, but in my experience each step was a new puzzle to figure out, and the satisfaction of finally making it work is one of my favorite parts of coding.
Being able to learn along the way is part of what made working on this project such an exciting and interesting experience. There were moments where we considered new insights and ideas, down to details such as using social media to launch the tool. As a Research Associate here at the SF Fed, I am able to implement projects involving complex data, and I would encourage anyone with an interest in working with data to try your own coding projects and see what you can create!